음원 데이터 전처리 (Audio Data Preprocessing)
음성 신호를 분석할 때 음성 파일에서 실제로 음성이 시작되는 부분만을 사용하고 싶을 수 있습니다. 음성이 시작되지 않는 부분은 불필요하기도 하지만 성능 저하나 추가적인 자원소모가 있을 수도 있을 것입니다. 이번 포스팅에서는 간단하게 음성 파일에서 음성이 시작되고 끝나는 부분의 앞과 뒤에 불필요한 부분을 잘라내는 방법을 다루어 보겠습니다.
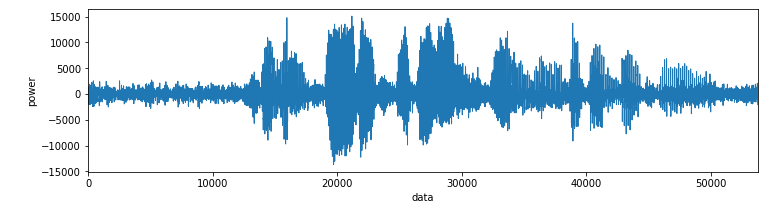
사진 설명을 입력하세요.
이번에 trimming할 source는 위와 같습니다. 참고로 라벨은 임의로 정한 것입니다. 사진의 그래프를 보면 앞과 뒤에 아예 소리가 없는 것은 아니지만 사람이 발화할때처럼 소리의 크고 작음이 변하지 않고 일정한 부분이 보이실 것입니다. 이 소리는 사실 차량이 내는 소리입니다. 도로에서 녹음이 되었는지 사람이 발화하는 상황에서 차 소리가 같이 녹음이 되고 있습니다.
다른 음원도 한번 보겠습니다. 파형을 비교해보면 차이가 확연히 납니다.

사진 설명을 입력하세요.
위의 그래프는 비교적 조용한 곳에서 녹음된 음원입니다. 사람이 발화하지 않을 때는 소리가 거의 없기때문에 trimming하기가 훨씬 수월합니다. 단순히 0또는 1보다 작은 크기의 소리를 가지는 부분을 추려내도 상당히 근접하게 잘라낼 수 있습니다.
하지만 실제로는 음성신호가 조용한 곳에서만 발생할리 없습니다. 내비게이션이 집에서만 음성인식 기능이 활성화된다면 아무런 쓸모가 없겠죠. 그래서 일반적인 상황에 두루 적용가능한 방법이 필요합니다.
저는 움성신호가 있는 부분만 골라내기 위해 하나의 표본을 잡아 librosa라이브러리의 trim메서드를 사용하여 임의의 값을 top_db값으로 설정하면서 적합한 top_db값을 찾았습니다. 그 후 이 음원과 다른 음원의 db값의 차이를 이용해서 top_db값을 음원에 맞게 조정하는 방법을 사용했습니다.
1. 필요 라이브러리 임포트
*참고로 리눅스계열의 서버 등에서는 librosa가 정상적으로 설치가 되지 않을 수 있습니다.
pip를 업그레이드 해주고 다시 설치하면 정상 설치가 될 것입니다. (pip install --upgrade pip)
코랩같은 환경에서는 설치가 필요하지 않습니다.
import pandas as pd
import librosa
import math
import sys
import csv
import numpy as np
import jsondb값을 구해줍니다.
stftResult=librosa.stft(y,n_fft=4096,win_length=4096,hop_length=1024)
D=np.abs(stftResult)
S_dB=librosa.power_to_db(D, ref=np.max)
db_df = pd.DataFrame(data=S_dB)des = db_df.describe()
desdb_mean = des.loc['max'].mean()
db값의 최곳값 평균을 구해줍니다.
real_time = len(y)/sr
real_time원래 음원의 실행시간을 구해줍니다.
log_rate = 10 * math.log10(db_mean/ -8.5)
print(log_rate)
topDB = 12 + log_rate
print(topDB)
clip = librosa.effects.trim(y, top_db=topDB)#14, 4
print(clip[1][0]/len(y)*real_time, '/', clip[1][1]/len(y)*real_time)기준치(-8.5)에 비해 지금의 음원의 db값차를 구해주어 trim메서드의 top_db값을 구하는 코드입니다.
아래 사진처럼 3.36짜리 음원이 0.85초 부터 3초까지 약 2.2초짜리 음원으로 줄어든 것을 확인할 수 있습니다.

감사합니다.