Listen, Attend and Spell 모델 implementation
1. OverView
[LAS: Listen, Attend and Spell 모델 개요]
pyramid birectual LSTM기반의 Listener와 Attention, Decoder가 결합된 모델로, seq2seq의 모델 구조와 비슷한 음성처리 모델이다. 이 모델을 기반으로 몇 가지 task들을 수행할 예정인데, 본 글에서는 구현을 다룹니다.
[Listener]
pyramid birectual LSTM의 경우 음성 신호의 길이가 길기 때문에 이를 해결하기 위해 적용되는 구조이다. 이 구조가 없으면 수렴이 늦어지는 등의 현상이 발생한다.
[Attention]
Scaled Dot Product Attention을 기반으로한 멀티 헤드 어텐션을 사용한다.
[Speller]
교사 강요(teaching force)를 적용한 Decoder이다. 단어 단위로 출력한다. beam serch를 이용할 수 있다.
label smoothing을 적용한다.
[데이터]
Librispeech 데이터를 사용한다. 이 데이터는 입력으로 로그 멜 스펙트로그램으로 변환되어 입력된다.
specAugmentation도 LAS를 기반으로 연구되었는데, 이 데이터 증강 기법은 로그 멜 스펙트로그램에 대해 적용된 데이터 증강기법이다.
[구조]
아래와 같이 listener와 speller가 연결된 구조를 가지고 있다.
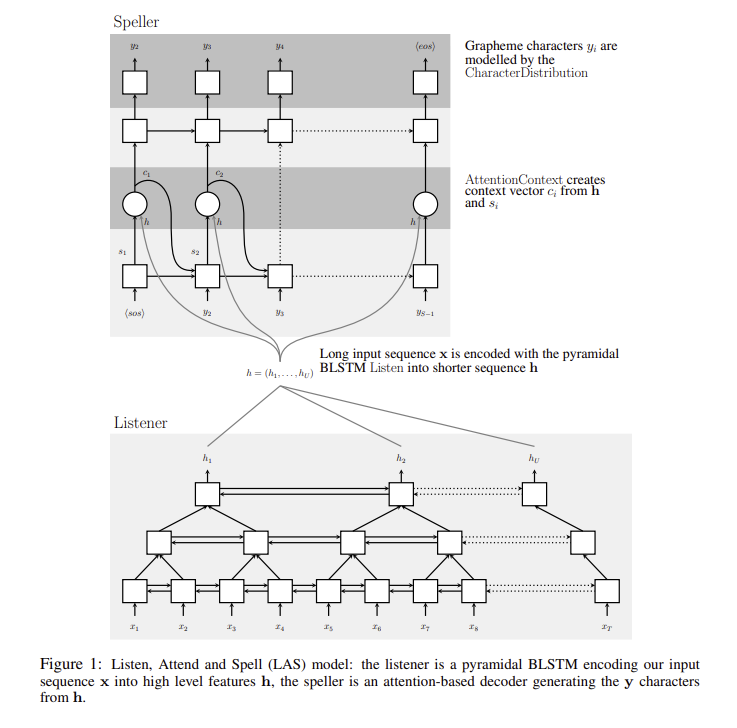
2. About Data
LAS모델의 입력으로 Libri Speech를 사용한다. 이 데이터는 다음과 같이 세부 데이터 종류가 있다.
dataset_list = [
"dev-clean", "dev-other", "test-clean", "test-other",
"train-clean-100","train-clean-360", "train-other-500"
]위의 데이터 셋 중 train데이터는 train-clean-100만 해도 약 6기가정도 되므로 개발시에는 300메가 정도의 dev-clean데이터를 사용한다.
데이터 셋의 getitem은 아래처럼 x를 변환한다. x의 경우 specAugment를 적용하려고 하면 log mel spectrogram으로 변환할 수 있다.
audio, sample_rate, label, _, _, _ = self.dataset[idx]
x = torchaudio.compliance.kaldi.fbank(audio, num_mel_bins=CFG.n_mels).t().unsqueeze(0)
x = x[0,:,:].squeeze(1).t()
y = []
y.append(SOS_TOKEN)
for char in label:
try:
y.append(self.char2id[char])
except:
y.append(self.char2id['<unk>'])
y.append(EOS_TOKEN)
y = np.array(y)
return (x, y)로그 멜 스펙트로그램으로 변환하고자 한다면 아래의 링크처럼 할 수 있다.
self.mel_converter = torchaudio.transforms.MelSpectrogram(sample_rate=CFG.sr, n_fft=CFG.n_fft, hop_length=CFG.hop_length, n_mels=CFG.n_mels)
self.db_converter = torchaudio.transforms.AmplitudeToDB() #convert value to log첫번째 줄은 멜스펙트로그램을 만들고 두번째 줄은 이 멜 스펙트로그램을 로그 스케일로 변환한다.
결과물은 아래와 같다.
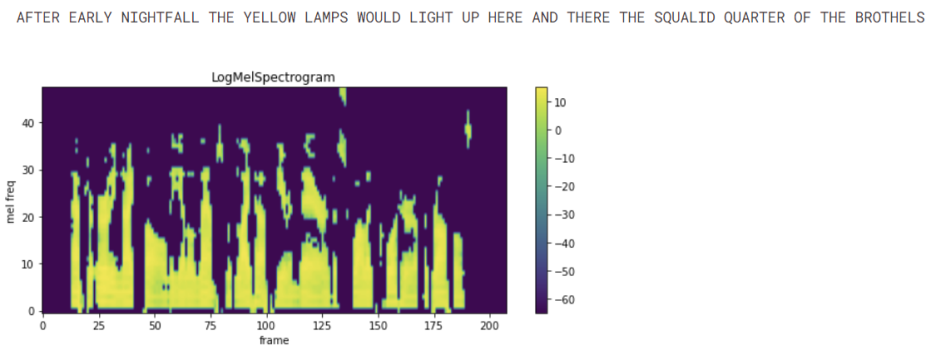
3. Augmentation
Las모델은 specAugment를 적용할 수 있고 굉장히 효과적입니다. specAugment의 implementation은 간단하지만 LAS의 범주를 넘어사므로 자세한 설명은 생략하고 출력 예시만 보여 드리겠습니다.

4. Architecture
listener
LAS모델은 피라미트 bi LSTM구조를 사용하고 이 피라미드 구조는 3개의 층으로 이루어져 있다. 구조는 아래와 같다. 해상도를 8분의 1로 줄이는 구조이다.
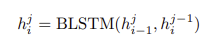
이렇게 bi LSTM을 쌓는게 listener의 구조의 핵심이자 사실상 그 자체라고 할 수 있다.
Attention
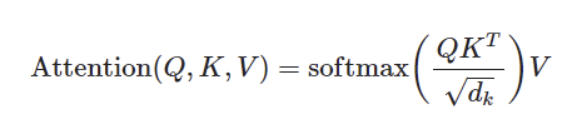
기본적인 어텐션은 간단하다. 위의 식을 그대로 코드로 옮기면 다음과 같다.
class ScaledDotProductAttention(nn.Module):
def __init__(self, dim):
super(ScaledDotProductAttention, self).__init__()
self.dim = dim
def forward(self, query, key, value):
score = torch.bmm(query, key.transpose(1, 2)) / np.sqrt(self.dim)실제로는 멀티헤드 어텐션이 사용되는데, Key, Query, Value를 선형 레이어에 통과시켜 가중치를 곱하주는 형태로 만들고 헤드 수로 설정한 만큼 쪼갠 후 위의 어텐션을 적용하고 다시 합하는 방식이다.
query = self.query_projection(query).view(batch_size, -1, self.num_heads, self.dim)
key = self.key_projection(value).view(batch_size, -1, self.num_heads, self.dim)
value = self.value_projection(value).view(batch_size, -1, self.num_heads, self.dim)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
context, attn = self.scaled_dot(query, key, value)참고로 key와 value를 보면 아래와 와같이 projection함수의 입력이 동일하다는 것을 알 수 있다. 이 둘다 listener에서 넘어온 feature을 그대로 선형 레이어의 입력으로 쓰는 것이다.
key = self.key_projection(value).view(batch_size, -1, self.num_heads, self.dim)
value = self.value_projection(value).view(batch_size, -1, self.num_heads, self.dim)projection이라고 이름을 붙였으나 아래와 같이 일반적인 선형 층이다.
self.query_projection = nn.Linear(hidden_dim, self.hidden_dim)
self.key_projection = nn.Linear(hidden_dim, self.hidden_dim)
self.value_projection = nn.Linear(hidden_dim, self.hidden_dim)
Speller

speller는 위의 식을 코드로 옮기는 것인데, 이 부분은 어텐션처럼 식만 그대로 옮기기에는 수학식이 아니다.
약간 복잡한데, 그래도 위의 식은 아래 코드와 같다.
def forward_step(self,inputs, hc, listener_features):
decoder_output, hc = self.rnn(inputs, hc)
att_out, context = self.attention(decoder_output,listener_features)
logit = self.softmax(self.character_distribution(att_out))
return logit, hc, contextrnn층에 이전 상태에 대한 정보와 상태를 넣고, 이 feature를 어텐션의 입력으로 넣은 방식이다.
character_distribution도 선형 층으로, 역시 가중치를 곱해주는 역할을 위해 있는 것이다. 다만 실제로 아래에도 있지만 (Listen, Attend and Spell pytorch implementation | Kaggle)의 코드를 보면 코드 양이 많은데 beam search와 교사 강요 코드가 포함되어 있어서 복잡하다.
다만 교사 강요의 경우 긴 시계열 예측 문제에서 주로 사용되는데 시작 시점에서 100step뒤의 정답을 예측해야할 때 99번의 step의 영향을 많이 받을 수 밖에 없는데 99가 잘못 예측이 되면 100도 잘못 예측이 되기 때문에 100을 예측할때 99step의 모델 예측값 대신 정답을 입력으로 주는 방식이다.
이 코드의 경우 speller가 배치가 1인 경우와 1이상의 경우에서 형태가 다르게 출력되므로 speller에서 조건에 맞게 수정하거나 training과 evaluating코드에서 전치를 적용하고 배치 차원을 추가해줘야 한다.
배치가 1인 경우와 2인 경우의 speller출력 차원은 아래와 같다. 32의 경우 문자의 수로, A,B,C, 공백 문자 등 입력 및 출력 데이터를 인코딩 디코딩 하기위한 문자들의 집합의 크기이다. 즉, speller가 배치 크기가 2일때 [2, 127, 32의 형태가 되는데 127개의 step(문장의 길이)에서 각각의 step이 32개의 문자 중 각각에 해당할 확률을 담고 있는 형태이며, 1차원인 경우 step은 전치를 해주고 배치 차원을 추가해주면 동일한 형태가 된다.
torch.Size([32, 82]) torch.Size([1, 82])
torch.Size([2, 127, 32]) torch.Size([2, 127])