Museformer: Transformer with Fine- and Coarse-Grained Attention for Music Generation
Introduction
museformer는 음악생성을 위한 transformer기반 모델입니다.
self attention 매커니즘이 transformer구조가 음악의 복잡한 상관관계들을 잘 포착하도록 하였지만 긴 시퀀스(특히 음악은 문장 단위의 자연어 처리에 비해 굉장히 깁니다)와 음악의 구조 모델링에는 한계가 뚜렷합니다. 음악의 경우 대체적으로 반복되는 패턴이 나타나는데 이러한 부분들을 기존의 transformer가 잘 생성하지 못합니다.
그래도 긴 문장에 대한 처리가 자연어 처리 분야에서 요구되는 경우가 많았기 떄문에 이러한 긴 시퀀스를 처리하는 모델들은 있습니다. 대표적으로 Transformer-XL, Longformer, Linear Trasnformer가 있는데 앞의 두 모델의 경우 local focusing이 강하여 일정한 부분에만 집중하다보니 중요한 정보들을 잃기 쉽고, Linear Transformer의 경우 global approxamation이 강하여 연관된 부분간의 상관관계를 잘 포착하지 못하고 음악의 고유한 특징이라고 할 수 있는 구조의 부분적인 반복성을 잘 생성하지 못한다고 합니다. 그래서 museformer는 위의 두 가지의 특징적인 transformer부류를 통합하여 각각의 장점을 살리고 단점은 완화하는 모델로 설계가 되었습니다.
다만 위에서 긴 시퀀스를 처리하는 모델들이 저러한 단점을 감내한 것은 모델의 복잡도를 낮추기 위한 것인데, museformer는 이 복잡성을 낮추는 방식을 중요한 정보가 균일하게 음악 전체에 분포되징 않은 점을 하는 방식으로 대체한 것입니다. 따라서 음악에 최적화된 모델이리고 할 수 있겠습니다.
museformer의 생성물은 마이크로소프트 블로그에 게시되어 있습니다.
[링크] https://ai-muzic.github.io/museformer/
Museformer
기본적인 방식은 일번적인 transformer구조를 따르되, 구조적인 부분을 이해하는 fine grained attention과 그 외의 구조를 이해하는 coarse grained attention이 사용된 FR-attention이 기존의 self-attention module을 대체하는 것입니다.
3.2 Fine- and Coarse-Grained Attention
전반적인 작동 방식은 아래 그림과 같습니다.
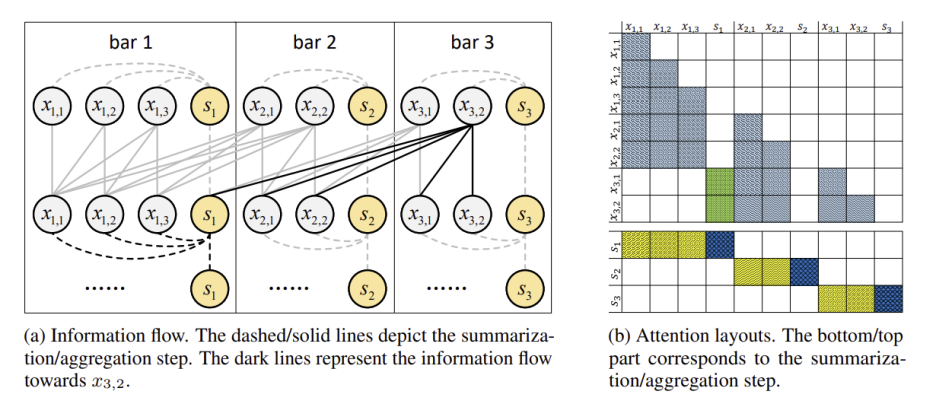
위의 그림은 이전 1개의 bar에 대해서만 구조와 연관된 bar로 취급을 하는 경우에 대한 예시입니다.
그림의 진한 부분 위주로 보면, bar3의 x들은 X3의 token들이고, 그림의 상황은 이 하나의 token x3,2가 다른 토큰들의 정보를 참조하려하는 것입니다. 그런데 이전 1개의 bar만 구조와 연관된 것으로 취급하는 상황을 전제하였으므로, fine grained attention은 이전 한 개의 bar인 bar2의 token들은 전부 직접적으로 참조를 하고, coarse grained attention은 bar1에서 x3,2로 이어진 진한 선이 s1에만 있는 것처럼 summary token만 참조를 합니다.
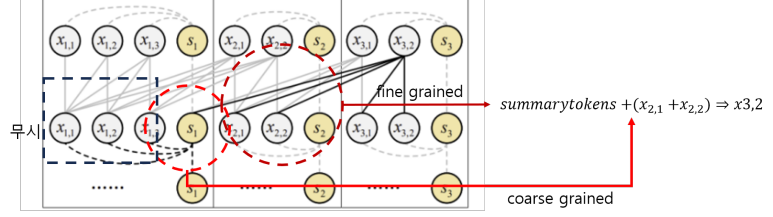
즉, 위와 같이 x3,2 token을 만들어내는 attention구조가 fine grained와 coarse grained구조가 결합된 것처럼 볼 수 있습니다.
summary token을 만들어 내는 과정도 그림에 진한 선을 보면 되는데, 자기 자신과 같은 bar내의 다른 토큰을 참조하여 summary토큰을 만들어 냅니다.
3.3 Structure-Related Bar Selection
museformer의 핵심인 fine- and coarse grained attention 구조의 경우 어떤 것이 structure related bar인지 구분하는 것이 중요합니다, 이에 따라 fine grained attention이 적용될지 coarse grained attention이 적용될지를 선택할 수 있습니다. 이를 위해서 유사도 통계를 통해 선택을 하게 됩니다.

수식자체는 간단하게 i번째 bar와 j번째 bar의 music notes집합에 대해, 합집합 분에 교집합으로 표현을 합니다. 그러니까 얼마나 music note원소가 겹치는지를 통해 bar간의 유사도를 산출하는 것입니다. 이렇게 bar와 bar간의 유사도 산출을 할 수 있게되었다면, 음악 자체에 대해 반복되는 구간이 어떻게 나타나는지를 위의 유사도 통계를 이용하여 '전체'에 대해 확인을 하면, 어떠한 규칙성을 찾을 수 있게 되고 이를 토대로 attention을 적용할 수 있게 됩니다.
전체에 대한 식은 다음과 같습니다.
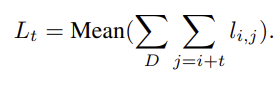
어떠한 간격 t를 두고 현재의 bar와 떨어진 bar를 비교대상인 j번째 bar로 보고 간격을 유지하면서 음악전체에 대해 확인해보면 됩니다.

논문의 본문에는 melody track에 대한 그래프만 있는데 appendix에는 다른 track에 대해서도 유사한 결과나 나타난 그래프가 있어 appendix 그래프를 첨부하였습니다. 이 그래프를 보면 예를들어 현재가 0간격인 지점인데, 4의 배수대로 분명한 유사성이 관찰되고, 2의 배수에 대해서도 꽤 주기적인 유사도가 관찰됩니다.
이를 토대로 1,2,4,8,12,16,24,32번째 bar를 선택하여 이를 structure related bar로 취급합니다. 많이 선택하면 더 좋을 수도 있지만 기존의 long sequence transformer들과 마찬가지로 긴 시퀀스를 처리하기 위해 컴퓨팅 자원 사용을 최적화할 필요가 있기 떄문에 일부만 선택을 하는 것입니다.
위의 링크에 몇 가지 museformer의 결과물들이 있으니 들어보시면 좋을 것 같습니다:)