wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
Introduction
세상에는 많은 언어들이 있습니다. 그런데 이러한 언어들 들모두에 대해 수천시간의 충분한 학습용 데이터를 얻기는 힘듭니다. 따라서 self supervised learning을 통해 구축한 사전학습 모델을 통해 적은 데이터를 가지고도 나름 괜찮은 수준의 음성 인식 모델을 구축하는 것이 목표입니다.
이산적인 인코더의 출력을 위한 gumbel softmax, 사전 학습 이후 fine tuning을 위한 CTC loss등의 방식을 사용하며 bert과 유사하게 masking하는 방식을 사용하여 적은 양의 데이터로 downstream task를 수행하더라도 꽤 좋은 성능을 보여줍니다.
Model

전체 구조는 위와 같습니다.
raw audio인 X에서 출발하여 여러 출력 결과들이 모여 학습이 진행됩니다.
1) Feature Encoder
기본적으로 raw audio를 입력으로 받는 모델이다보니 temporal convolution layer가 raw audio를 인코딩합니다.
2) Contextualized representations with Trainsformers
cnn layer를 활용해서 마치 relative positional embedding과 유사한 transformer base context network를 사용해 인코더의 출력을 처리합니다. audio 신호 자체가 cnn으로 어느 정도 차원 및 길이를 축소하더라도 기본적으로 신호의 의길이가 길기 때문에 relative positional embedding이 효과적인 것 같습니다.
3) Quantization module
self supervised learning을 위해 product quantization을 수행합니다.
product quantization은 임베딩된 신호를 다시 codebook(일정한 값들을 갖는 집합)에 포함된 entry값들에 근사 또는 매핑 시켜 이를 다시 합치는 방식입니다. codebook은 입력에 비해 상대적으로 작은 데이터 세트를 포함하므로 정적인 임베딩 같은 방식입니다. 이후 gumbel softmax를 통해 이산화된 출력을 미분가능하도록 합니다. VQ-WAV2VEC에도 소개되었었습니다.
일단 위의 방식을 다시 보면, codebook은 G개 있고 이 각각의 codebook에는 V개의 entry가 있습니다. 또 매핑시 각 codebook에서 하나의 codeword를 선택하는 방식으로 작동하는 것이기 떄문에 codebook을 선택할 필요는 없고 각 codebook내의 codeword만 선택하면 됩니다.
따라서 아래와 같이 각 codeword가 선택이 되는 확률을 정의하였습니다.
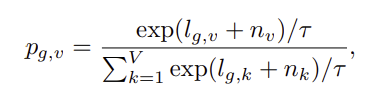
선택 기준이 확률이므로 codeword는 자연스레 확률이 가장 큰 경우를 선택하도록 i = argmaxjpg,j입니다.
Training
self supervised learning 모델이다보니 사전 학습은 contrastive learning을 하고 fine tuning은 CTC loss(발화속도, 길이 등에 따라 label값이 데이터와 시간상으로 일치하지 않는 문제를 위한 loss)를 사용하여 학습합니다.
다만 contrastive learning만으로 학습을 진행하지는 않고 목적함수를 아래와 같이 정의합니다.

contrastive loss에 가중치가 곱해진 diversity loss를 더해 정의합니다.
Contrastive Loss

양자화 모듈 자체가 contrastive learning을 위한 방식이었습니다.

위의 그림을 다시 보면 masking된 시간 스텝에서 하나의 context network의 출력(회색으로 칠해진 작은 사각형)이 주어지고 양자화 모듈을 통과한 작은 사각형에서의 출력이 보입니다. context network의 출력이 ct이며 이러한 상황에서 모델은 이 ct와 동일한 시간 스텝의 양자화 모듈의 출력 qt찾아야하며 동일 발화의 다른 시간 스텝의 양자화 모듈의 출력 q들은 분리를 하도록 학습을 합니다. 따라서 K+1개를 선택하게 되는 것입니다. (1개는 t스텝의 양자화 모듈의 출력일 것입니다. 즉 K개의 다른 후보군 distractor를 고르는 것입니다.)
Diversity Loss

위의 식으로 정의되는 loss입니다. codeword가 균등하게 사용되도록 하기 위한 loss입니다.